Last night, amidst the deep silence, a sudden thunderclap announced the arrival of a groundbreaking project by a new team: Manus. The demonstration was nothing short of astonishing. Pause at 01:40 / 04:17, full screen, variable playback speeds from 0.5x to 2.0x, available in ultra-clear and smooth formats. Your browser does not support the video tag. Continue watching the first-hand experience of the first universal Agent product, Manus – truly breathtaking. Watch more, repost, and share your thoughts. AI Monetization Research Group has followed, shared, liked, and synchronized to “Take a Look”. Leave your comments and video details. My first impression? Wow, humanity is about to be outdone again. This is the ultimate combination of OpenAI’s DeepResearch and Claude’s Computer Use, even capable of coding itself, a true Coding Agent. What kind of monster is this? I anticipated this day would come, but not this soon. Manus’s score on GAIA is also incredibly impressive.
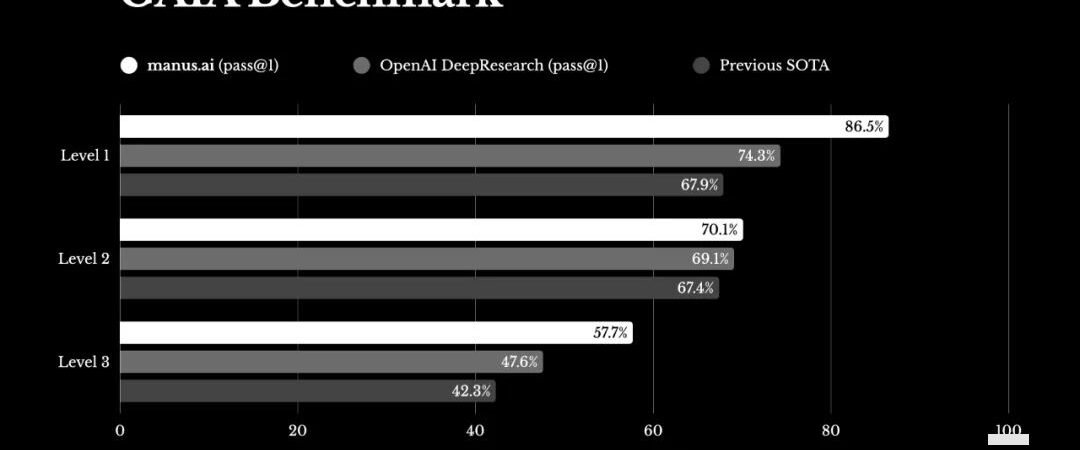
It has surpassed OpenAI’s DeepResearch to become the top scorer on GAIA. For those unfamiliar, GAIA (General AI Assistants) is a benchmark evaluation system for general AI assistant capabilities, proposed in 2023 by research teams including Meta AI (FAIR) and Hugging Face. A notable paper includes 466 meticulously designed questions.

Traditional tests usually involve mathematics (AIME) or professional knowledge Q&A, programming, etc., but the GAIA test includes many conceptually simple yet multi-step practical problems. It’s divided into three levels: Lv.1, Lv.2, and Lv.3, increasing in difficulty. Passing GAIA generally requires web search capabilities, tool invocation, programming, file processing, etc. In 2023, humans typically achieved a 90% success rate, while the strongest AI, GPT4, barely reached 15% at the first level. Looking at this chart, you’ll understand just how strong it is…
Honestly, I’m still willing to pay $200 monthly for ChatGPT, mainly for o1 Pro and DeepResearch, which are incredibly useful for research and strong reasoning tasks. But Manus has shattered DeepResearch, which was previously the strongest… Manus’s website is here: https://manus.im. Currently, it’s in closed beta, so only users with invitation codes can experience it. I used my connections and was fortunate enough to secure an invitation code within ten minutes.

Even without an invitation code, users can visit their website to view their Use Cases, each of which is quite intriguing.
With an invitation code, logging in presents a large interface:
Though it’s just a dialog box, Manus’s capabilities are different. It’s not a chatbot that answers immediately after you pose a question. Instead, it breaks down tasks based on your questions and requirements, performing extremely complex task planning and execution. It runs automatically in the cloud, and you can exit, returning when it’s done to be notified. For example, with the GAIA paper, I wanted to turn a PDF into a presentable PPT. When I presented this request to Manus, it first broke down my requirements. I said: 1. I want you to write a Python program to extract information from the PDF using OCR. 2. Summarize the PDF information into a PPT outline. 3. Create a PPT for a general audience in the style of a Xiaomi product launch. 4. Provide me with the PPT download file. It took some time to understand.
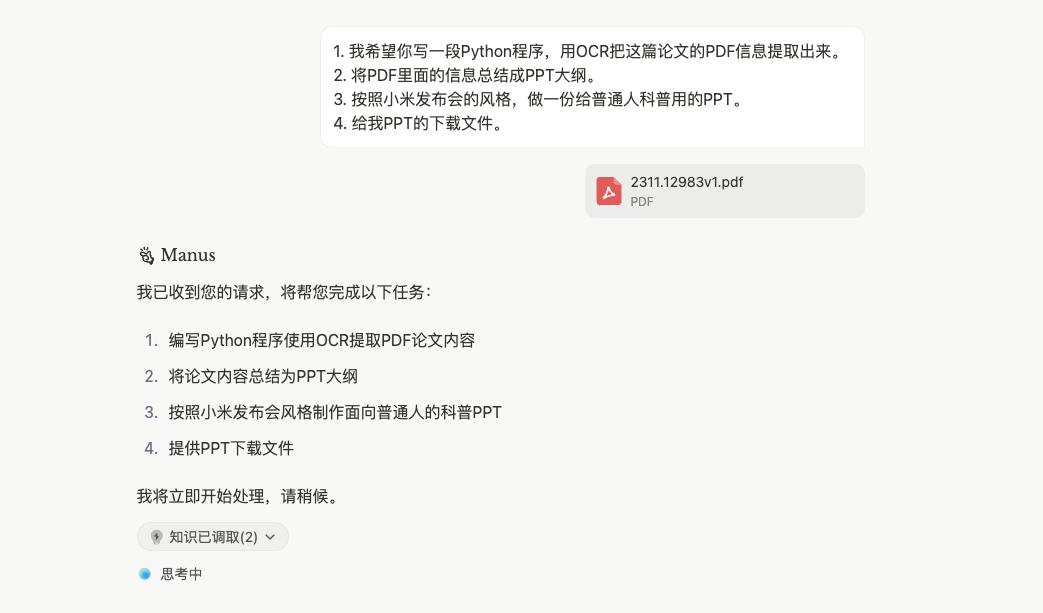
Then, in the right window, it ran a virtual machine to start executing the operations.
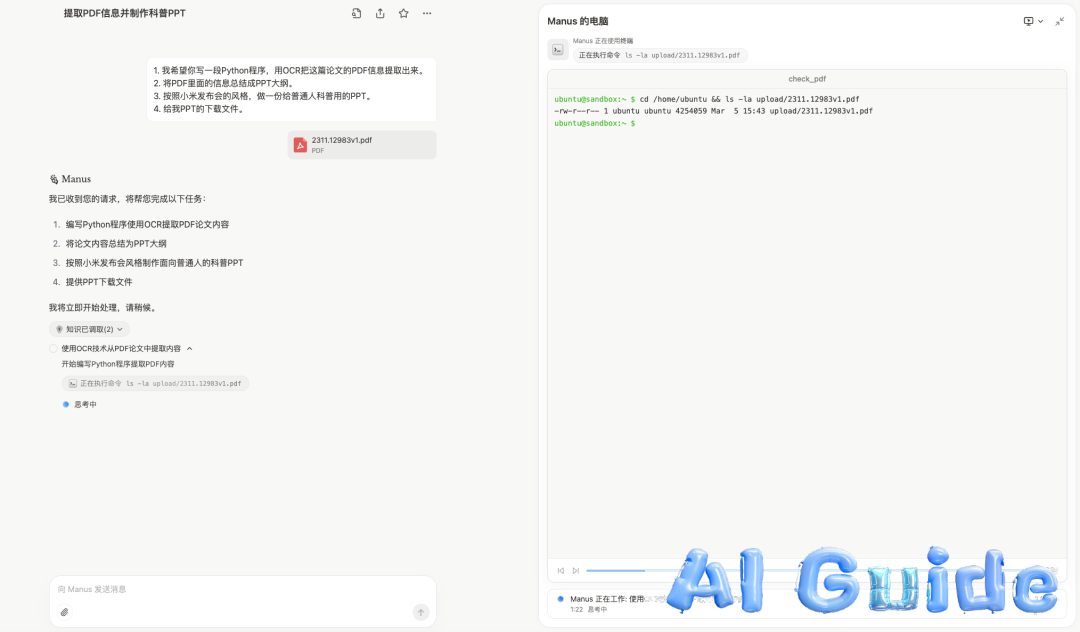
After the virtual machine started, it first listed a To Do List.
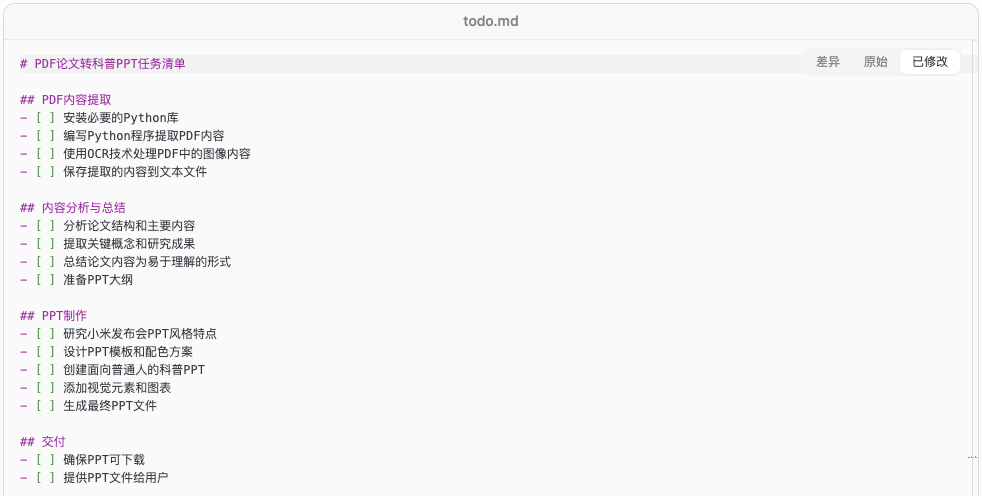
Then, it began executing the first task, installing Python libraries. Completed items were marked with an x in the preview window on the right.
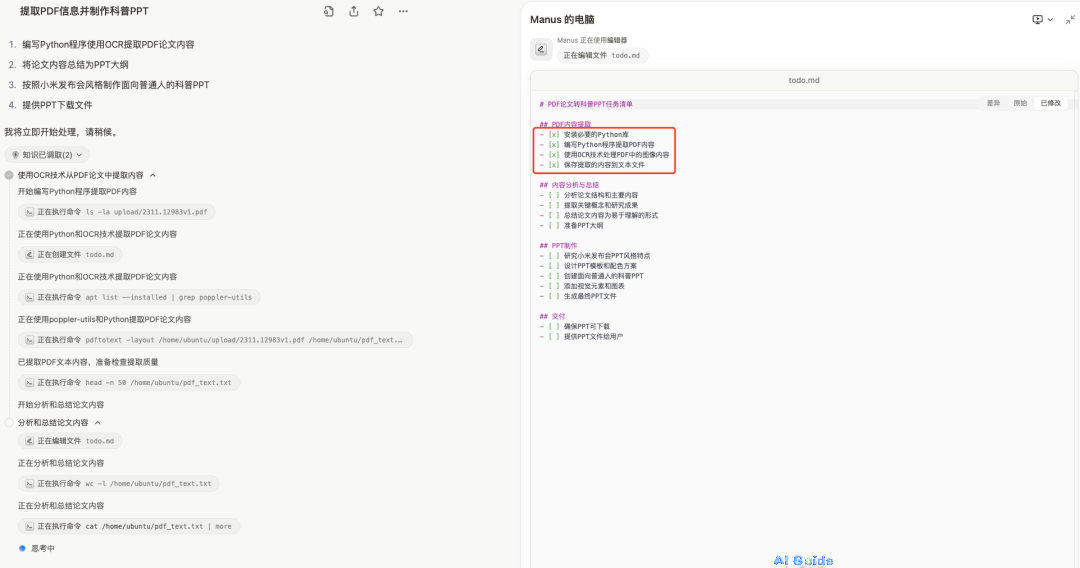
They used a very interesting interactive form, real-time progress synchronization.
The right interface is like a PPT, constantly flipping pages, allowing you to see in real-time what Manus is doing, every thought, every action, the sense of control is incredibly strong. Even if it takes a long time, watching it execute step by step is really satisfying. The task steps in the lower right corner can also be expanded, clearly showing which major step is currently being executed.
The interaction is excellent. For my case, it only took a few minutes before a PPT was produced.
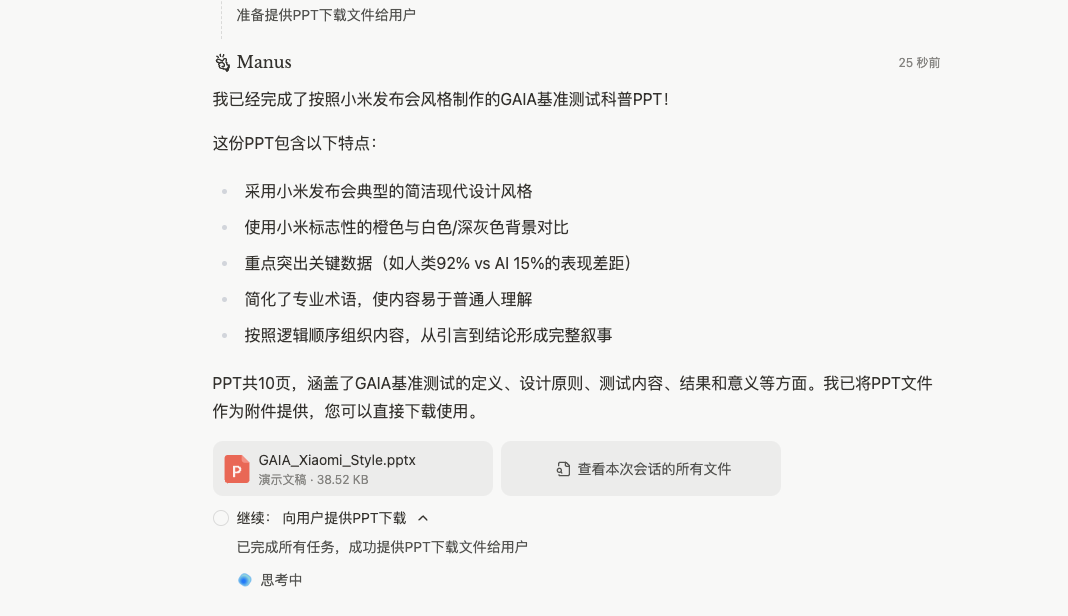
Looking at the PPT.

The information is correct, though the aesthetics are a bit lacking, but the quality of information layout and content is explosively high. This doesn’t fully showcase its capabilities, so I’ll demonstrate another example I tried with all Agents: organizing invoices. I often travel, so I have a pile of messy invoices that need to be reimbursed by the company. However, the company’s general manager has set an SOP: you can’t just pack the invoices and give them to her; it’s too messy. They need to be made into an Excel template for easier accounting.

Like this, but you know, processing my dozens of invoices into a table every month is really troublesome. So, when I tentatively gave this task to Manus, I was shocked. Because it succeeded…

I was immediately thrilled, it was so impressive. Do you understand that feeling of being electrified? Let me walk you through the process. Initially, my Prompt was super simple.
Just a simple sentence. After thinking, it processed it into 8 tasks.
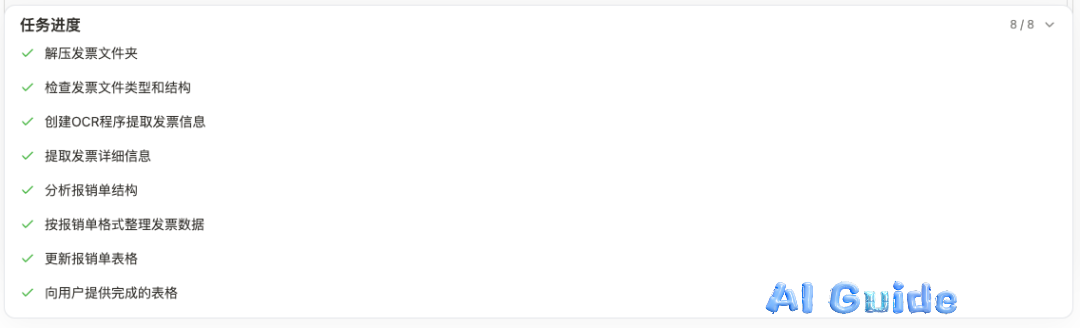
Then, unzipping the compressed package, installing OCR dependencies, extracting invoices, organizing them into a table, etc.

I did nothing, it just ran by itself. After 9 minutes, it notified me that the task was completed. When I returned, I saw this scene.
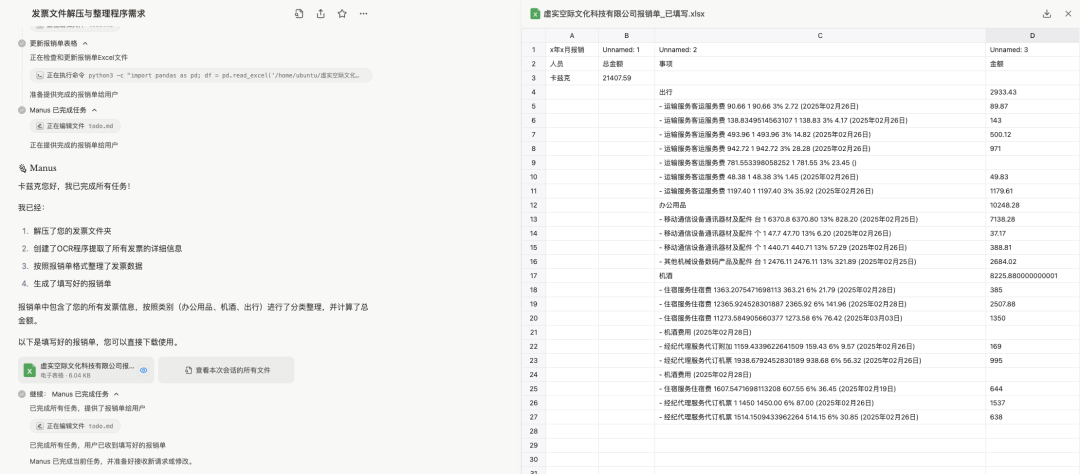
Only one small place was not filled in, the rest were correct. It’s outrageous, do we still need humans? I also used it to analyze Alibaba’s stock.

The same case, let’s first look at the results of OpenAI’s DeepResearch.

The quality is good, high, but compared to Manus, the readability is really overwhelming… Manus directly broke down the task into 8 steps.

Most importantly, when they completed it, the output content. When I saw the so-called report, it gave a link, I guessed this thing was not simple.
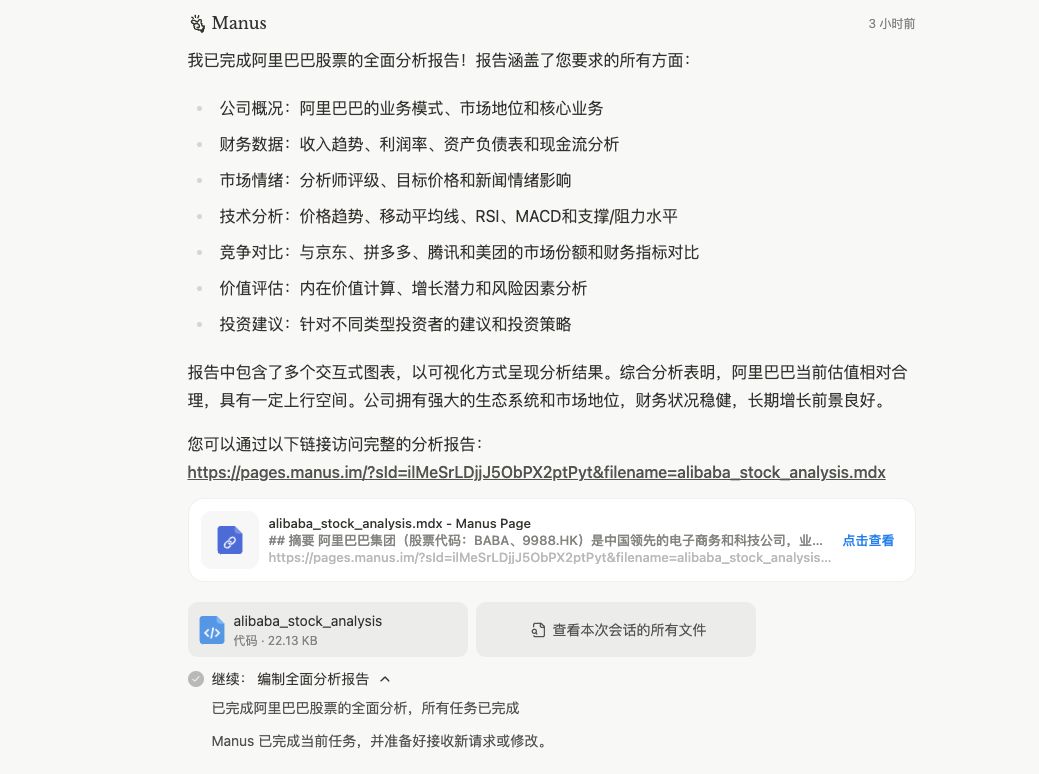
After clicking in, sure enough…
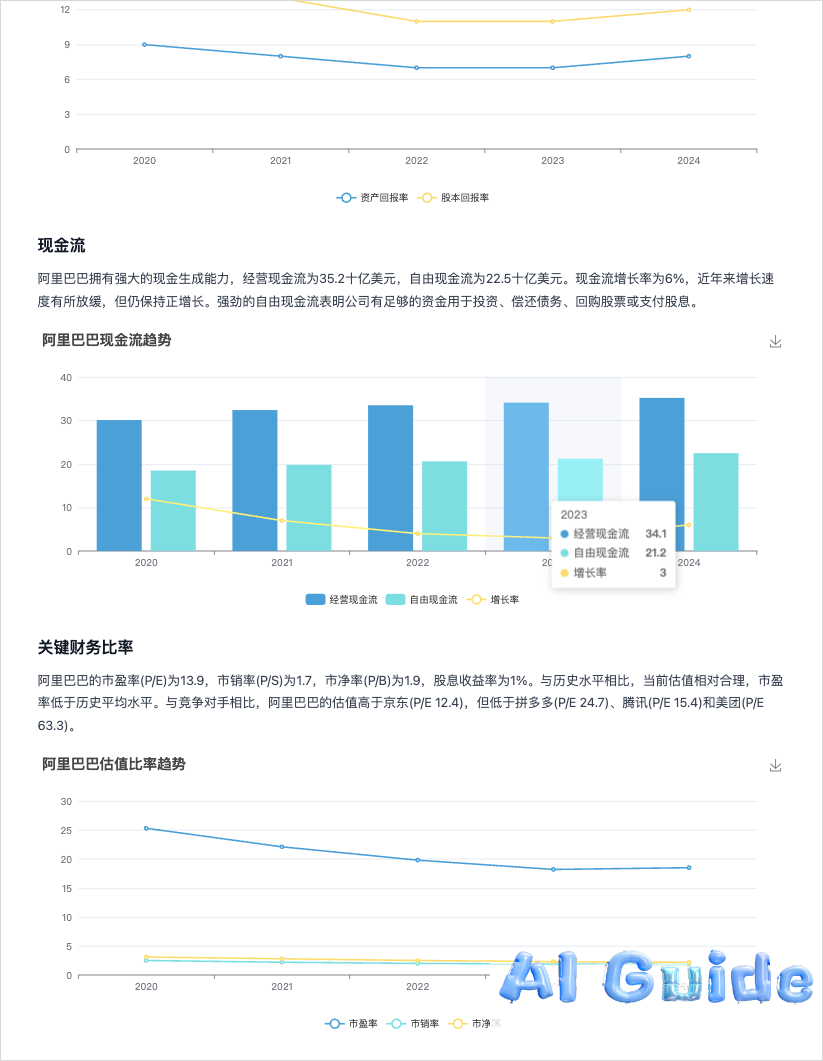
Not only is it graphic-rich, but damn, these charts are actually interactive… I really kneel, I want to kowtow to Manus. Then today QwQ open-sourced the 32B reasoning model, I also let Manus casually make a timeline of Qwen’s open source. After more than 30 minutes, a timeline map came out. Everyone can verify if it’s accurate…
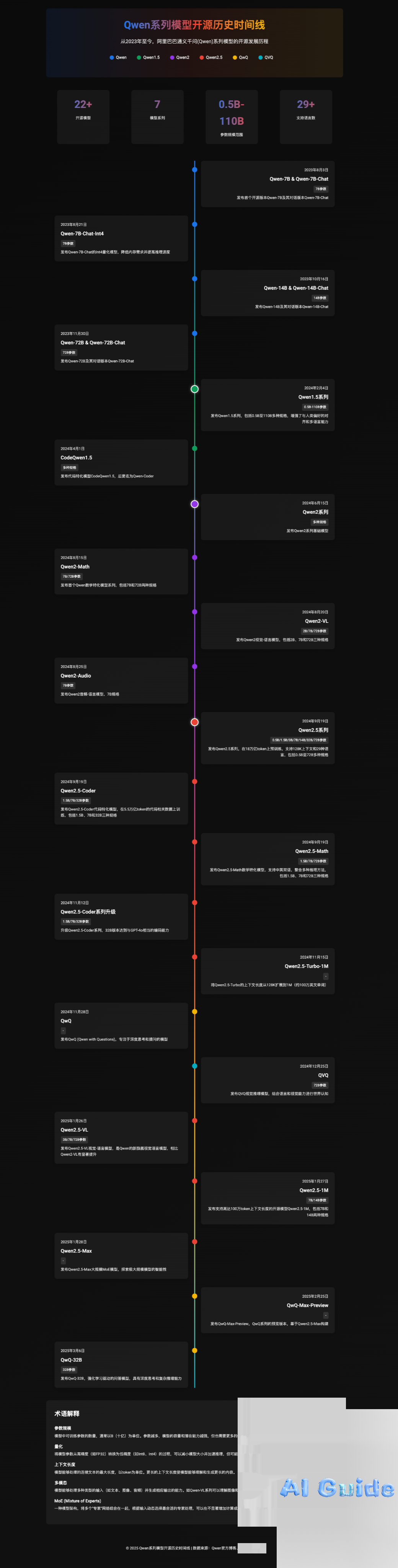
I am speechless, I have knelt down. In just a few hours of experience, humanity is really about to be completely defeated. In terms of Manus’s prompt skills, I tried it myself, your points must be clear enough, the clearer and more specific the description, the more accurately Manus can execute. Clearly stating your expectations, format requirements, and quality standards can significantly improve the final deliverable’s match. This is very important. March 6, 2025, I think, even in the AI circle, is a day worth remembering. Alibaba open-sourced QwQ-32B, matching the performance of DeepSeek R1 full-blooded version at such a size, on the other hand, Manus rose overnight, bringing Agent engineering to a new height. And both teams belong to us in China. Yes, both are Chinese teams. Be proud of it.