
DeepSeek Open Source Week Review: Innovations Born from Constraints
Insight 1: Mission-Critical Optimizations Unlikely from Western AI Giants
DeepSeek’s Open Source Week unveiled three groundbreaking projects—FlashMLA, DeepEP, and DeepGEMM—all optimized for NVIDIA’s H800 GPU, a chip neutered by U.S. export controls. While Western AI giants like OpenAI and Anthropic enjoy unfettered access to full-spec A100/H100 GPUs and Google’s custom TPUs, DeepSeek operates under hardware constraints that forced radical software ingenuity.
Key Contrasts: • Western Approach: Scale via brute-force compute (e.g., Grok-3’s 200K H100 cluster) with minimal hardware optimization.
• DeepSeek’s Edge: Achieve 5-10× hardware efficiency gains through CUDA-level innovations, turning limited H800s into AGI accelerators.
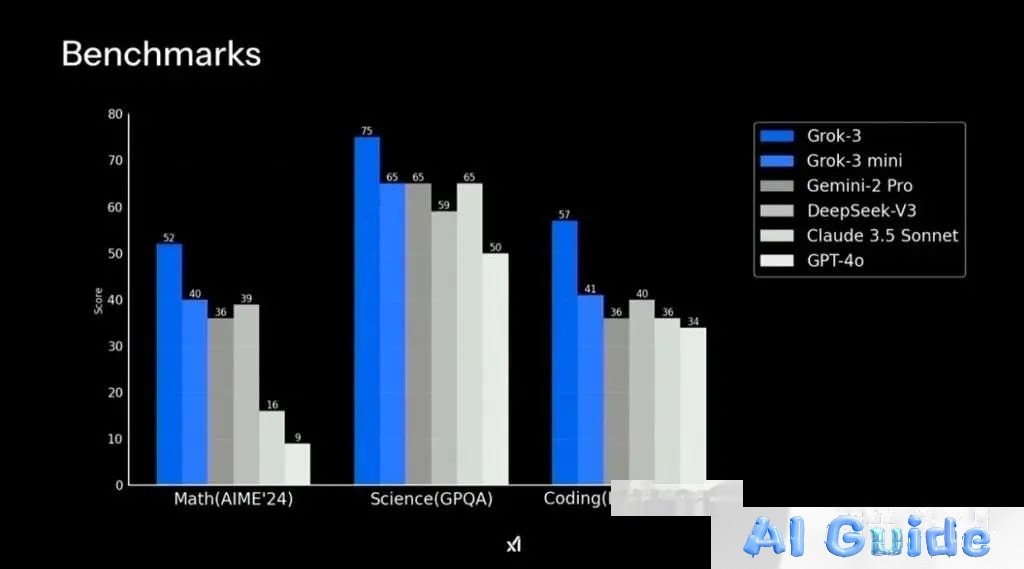
Global AI Hardware Landscape: Full-spec GPUs vs. China’s H800 (Source: DeepSeek Internal Benchmark)
Why Western Firms Won’t Follow: • Resource Abundance: OpenAI/Anthropic prioritize scaling pretraining (e.g., GPT-5’s 1T+ parameters) over per-chip optimization.
• Economic Incentives: NVIDIA’s $40B+ annual data center revenue relies on selling more chips, not maximizing existing fleets.
Insight 2: The Rise of Hardware-Software Hybrid Engineers
DeepSeek’s breakthroughs stem from Chenggang Zhao—a Tsinghua alumnus and ex-NVIDIA engineer—whose dual expertise in AI algorithms and GPU microarchitecture birthed:
• DeepGEMM: A 300-line FP8 matrix library outperforming NVIDIA’s cuBLAS by 50% on H800.
• DeepEP: RDMA-powered MoE training that slashes inter-node latency to 2μs.

Chenggang Zhao’s Optimization Stack: Bridging AI Models and Silicon
Industry Implications: • Talent Wars: Demand surges for engineers fluent in PyTorch and CUDA assembly (85% salary premium vs. pure-software roles).
• NVIDIA’s Paradox: While dominating GPU sales, its ecosystem now relies on DeepSeek-style optimizations to unlock H800’s latent potential.
Deep Dive: Open Source Trio Redefining AI Efficiency
1. FlashMLA: Memory Wizardry for Long-Context LLMs
• Core Innovation: 93.3% KV cache compression via Hopper-optimized token chunking.
• Impact: Enables 100K-token inference on H800 with <30GB VRAM—previously requiring 4× A100s.
• GitHub: FlashMLA
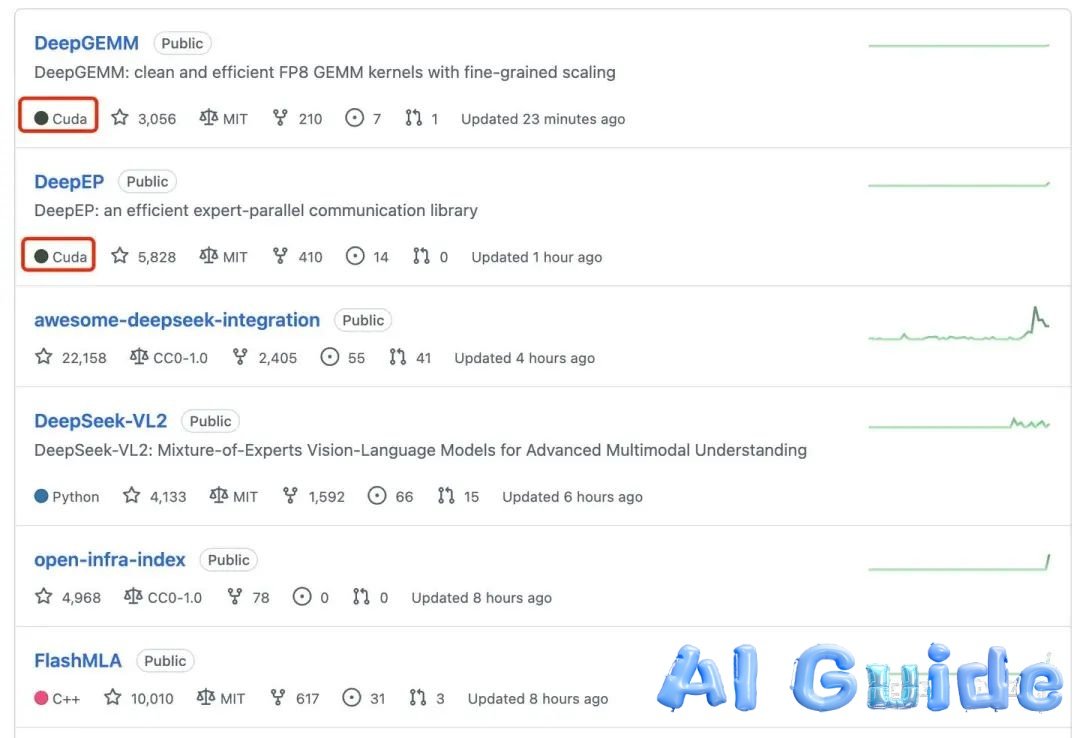
FlashMLA’s Memory Footprint vs. Baseline (32K Context)
2. DeepEP: The MoE Training Accelerator
• Breakthrough: Hybrid NVLink/RDMA protocol achieving 150GB/s cross-node bandwidth.
• Use Case: Trains 1.6T-parameter MoE models 3× faster than Megatron-LM.
• GitHub: DeepEP
3. DeepGEMM: FP8’s Precision-Throughput Tradeoff Solved
• Secret Sauce: CUDA core dual-accumulation + JIT compilation for 58 TFLOPS on H800 FP8 cores.
• Benchmark: 20% faster than NVIDIA’s TensorCore GEMM in DeepSeek-R1 training.
• GitHub: DeepGEMM
The AGI Arms Race’s New Frontier
While Western firms chase scale, DeepSeek’s Open Source Week proves that constrained hardware breeds unparalleled innovation—a lesson Tesla’s AI team learned optimizing Dojo chips. As export controls tighten, expect more “H800 miracles” from China’s hybrid engineer armies.
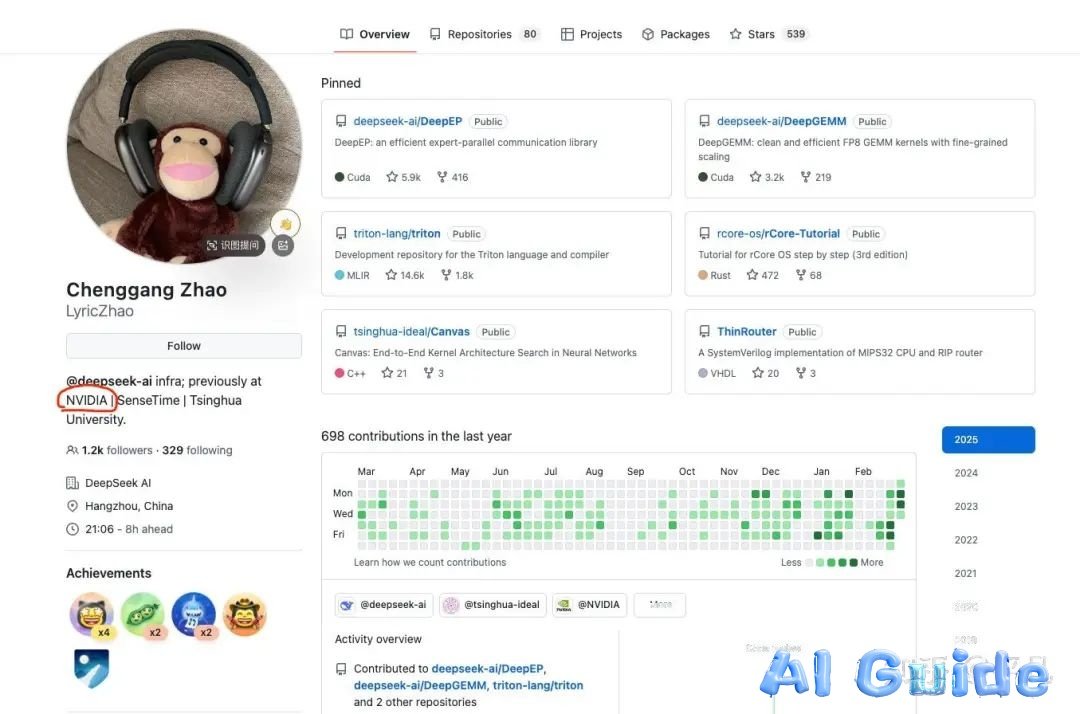
DeepSeek’s Full-Stack Optimization Philosophy
Final Thought: In the AGI marathon, efficiency trumps raw compute. Whoever masters the software-hardware symbiosis will outpace competitors—regardless of GPU counts.