
DeepSeek V3’s “Minor Update” Performs Like V3.5—Even Non-Reasoning Models Have Their “Aha Moments,” Solving the 7m Sugarcane Through a 2m Door Puzzle
DeepSeek V3 has been upgraded to a new version—V3-0324. The official announcement downplays it as just a “minor update,” but real-world testing suggests it’s anything but small.

It aced the popular bouncing ball test even when scaled up to a 4D hypercube. [Duration: 00:14]
Good grief—if this is just a minor update, I can’t even imagine what a major one would look like.

In coding tasks, a single prompt was enough to generate a fully functional product landing page with adaptive layouts and dynamic effects—performance on par with Claude 3.7 Sonnet.
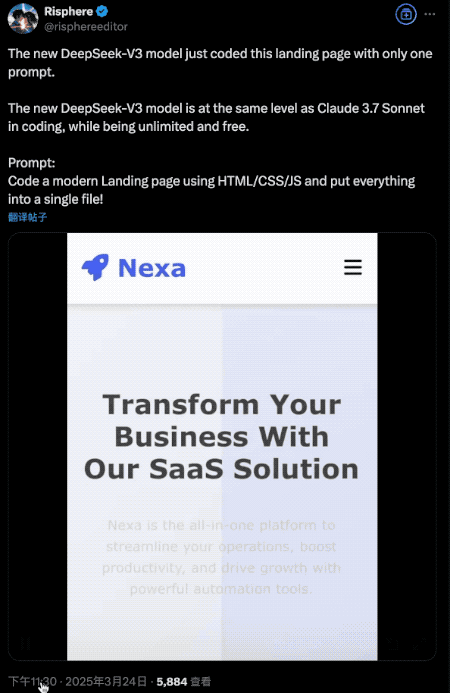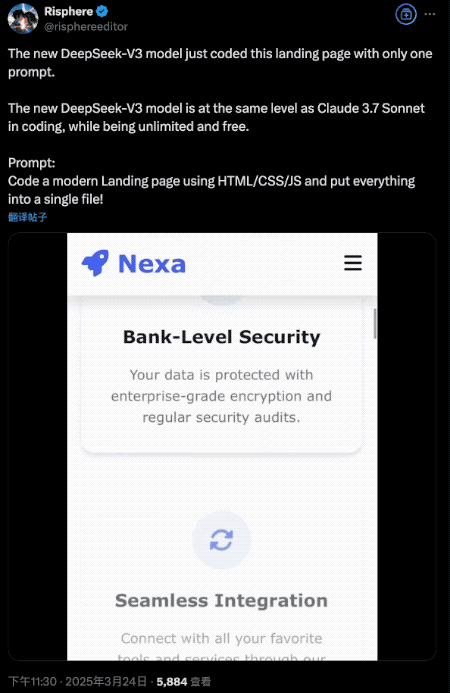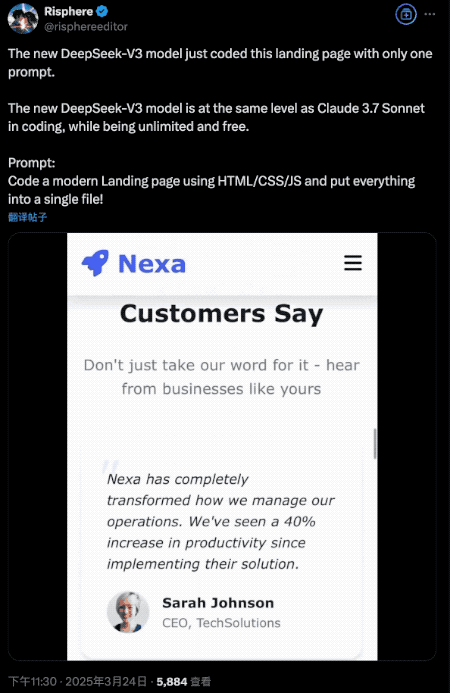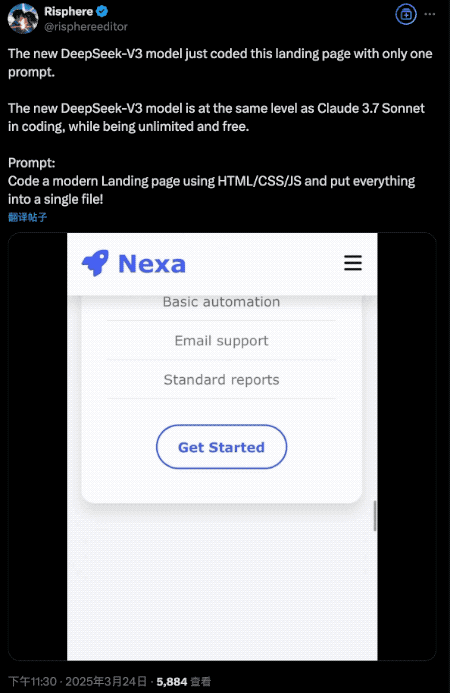
Since its release is still fresh, formal benchmarks aren’t available yet. However, in developer Xeophon’s personal benchmark suite, it showed significant improvements across all metrics, emerging as the best non-reasoning model tested.
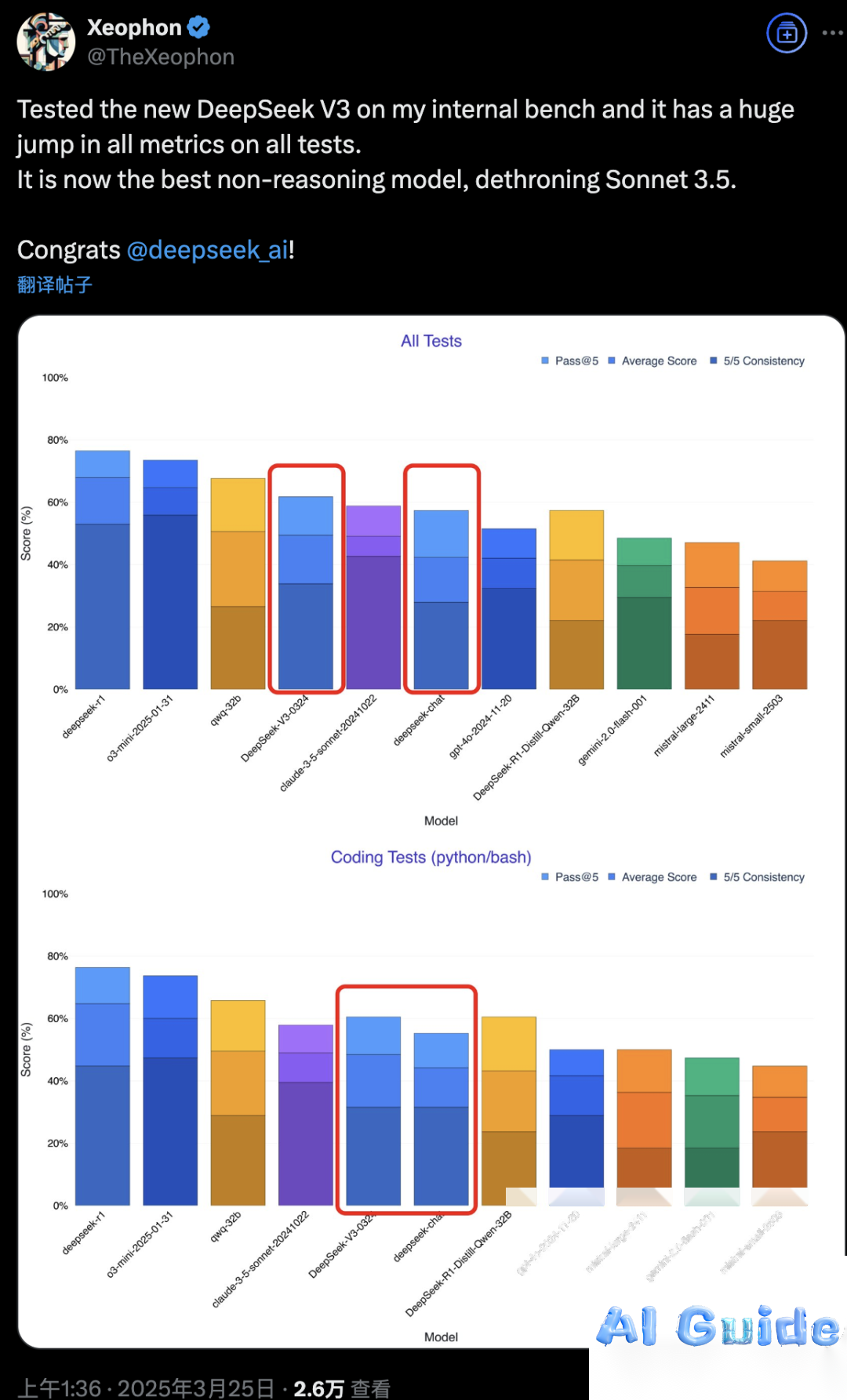
Even Non-Reasoning Models Have Their “Aha Moments”
DeepSeek-V3-0324 isn’t a reasoning model—it doesn’t show its thought process before answering—yet it still systematically breaks down problems. When hitting a dead end, it demonstrates the ability to backtrack and reassess.
While questions like *”Is 9.11 greater than 9.9?”* or *”How many ‘r’s are in ‘Straberry’?”* are trivial for modern AI, the new torture test is:
*”How can a 7-meter-long sugarcane pass through a 2-meter-tall, 1-meter-wide door?”*
In QuantumBit’s testing, DeepSeek-V3-0324 initially stumbled, much like its predecessors and many other AIs.
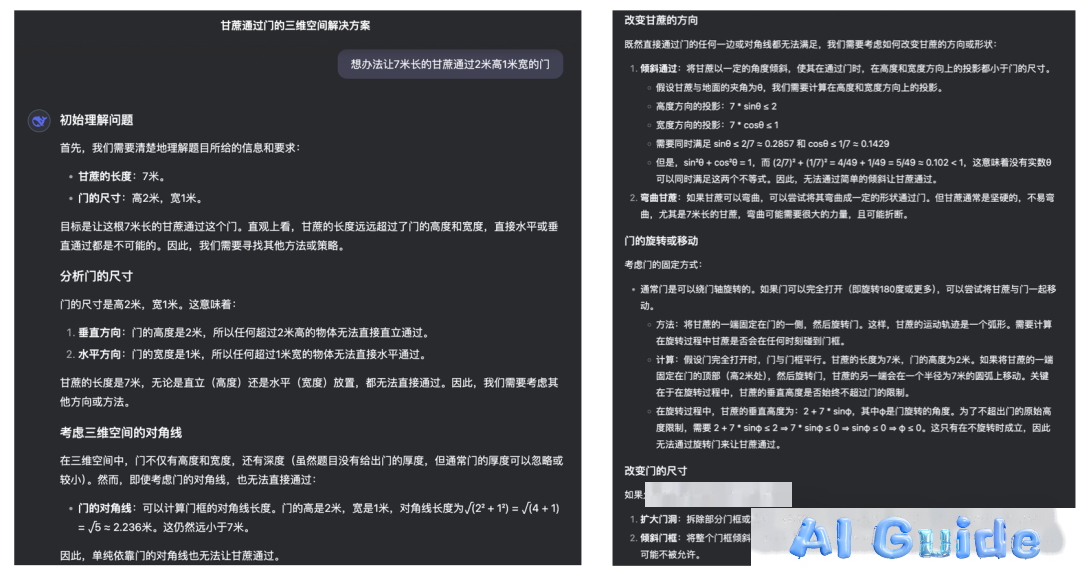
After hitting the wall, it began re-evaluating the question’s meaning. It still wandered into misconceptions, but then—an “Aha Moment”—midway through Chinese reasoning, it suddenly switched to an English thought, reminiscent of the *”Eureka”* breakthroughs in DeepSeek-R1’s technical report:
*”Wait… this seems similar to the diagonal method. Maybe I missed something.”*
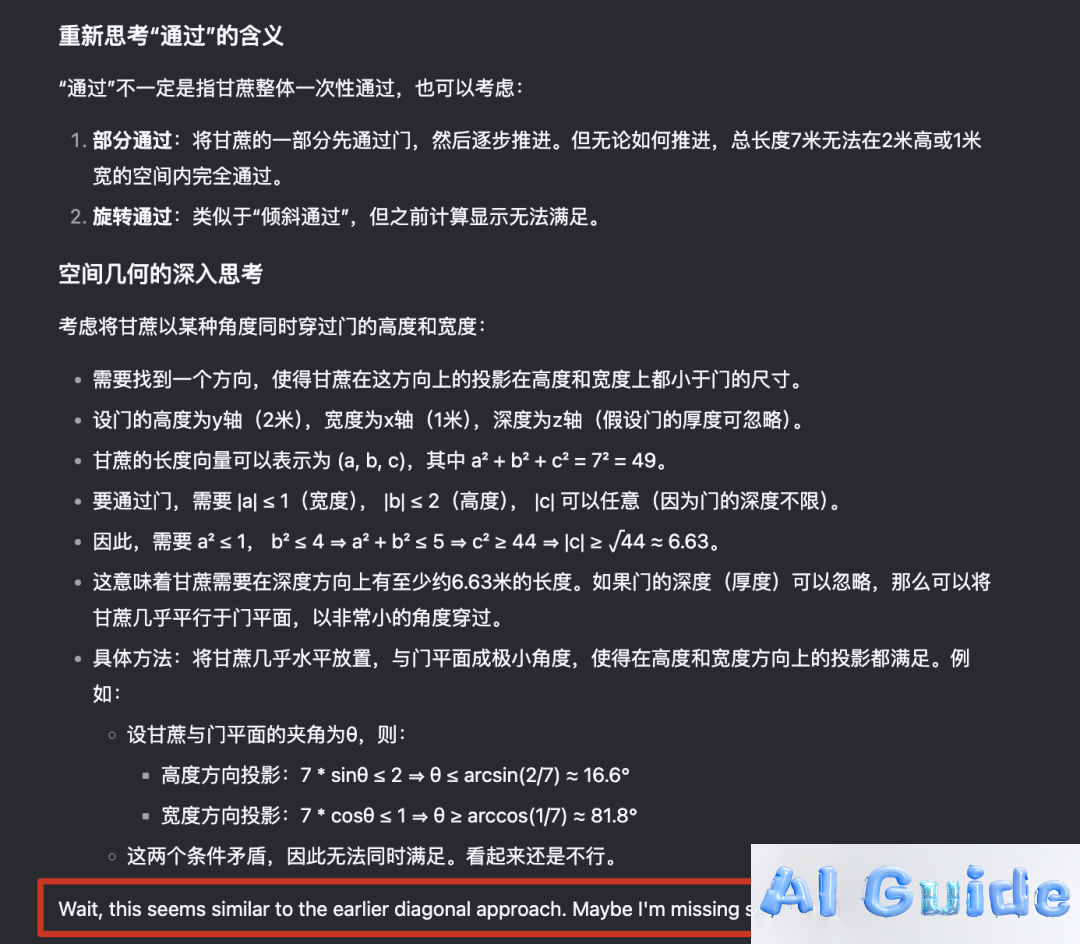
Following this spark of insight, it pivoted toward the correct approach, uncovering hidden conditions not explicitly stated in the problem.

Though its calculations still didn’t fully grasp the core of the puzzle, it arrived at a viable solution—and even recognized its earlier mistakes.

Still Free. Still Open-Source.
Despite its impressive capabilities, this model remains free and open-source, with weights already available on Hugging Face under the permissive MIT license.
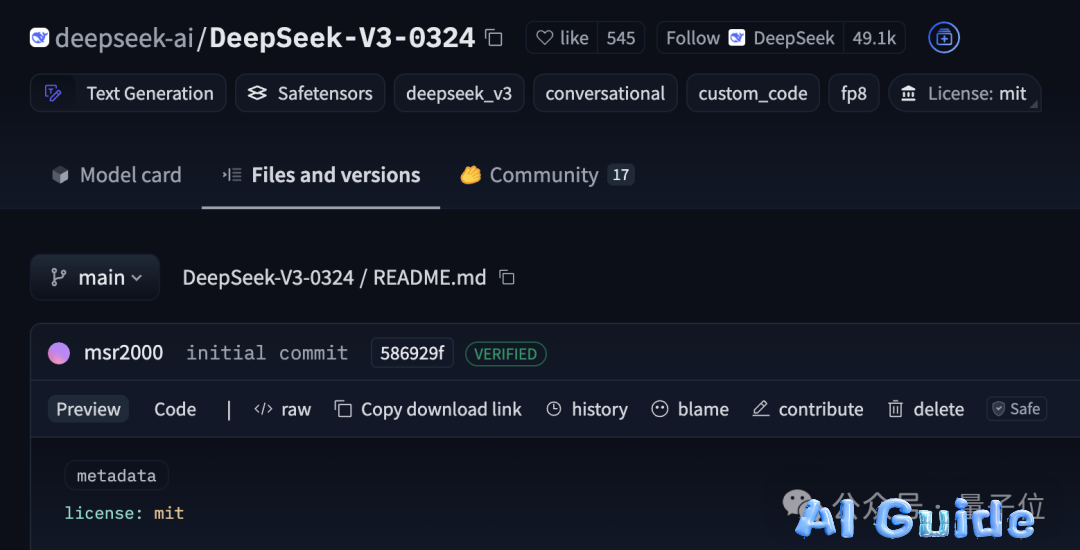
The total weight files occupy ~688GB of storage—consistent with the original V3, confirming it’s still a 671B MoE (Mixture of Experts) model. Further technical details await an official announcement.
You can try V3-0324 now on:
- The official website
- The DeepSeek app (disable Deep Thinking mode)
- Hugging Face

You can also pit it against other models on the LLM Arena, though voting results will take time to aggregate.
Of course, the burning question now is: If V3 is already this good… how close is R2?
References:
[1] https://x.com/TheXeophon/status/1904225899957936314
[2] https://x.com/Yuchenj_UW/status/1904223627509465116
[3] https://x.com/risphereeditor/status/1904194061780590773