
Google’s AI Revolution: Gemini 2.0 Redefines Image Generation with Mind-Blowing Capabilities

The AI landscape just witnessed another seismic shift. Google has unleashed the full potential of Gemini 2.0, its multimodal AI system, through an experimental preview on AI Studio. What we’re seeing isn’t just incremental progress—it’s a paradigm shift in real-time image manipulation. Let’s break down the groundbreaking features and their industry implications.
1. Instantaneous Visual Transformation: A New Era of Creativity
Upload an image of a girl, type “make her hair short,” and within 10 seconds, Gemini 2.0 delivers photorealistic results. Want her wearing a basketball jersey? Another simple prompt, and the AI reimagines her outfit flawlessly.
Why this matters: • Precision Editing: Unlike traditional tools requiring manual masking, Gemini 2.0 leverages advanced diffusion models to preserve original lighting and textures while modifying elements.
• Contextual Awareness: The system analyzes spatial relationships (e.g., how hair interacts with shoulders) to avoid uncanny artifacts.

2. Industry Disruption: The Death of Manual Photo Editing?
Graphic designers, photographers, and e-commerce retouchers face an existential challenge. Gemini 2.0’s capabilities—demonstrated through use cases like object removal, colorization, and expression editing—threaten to automate workflows that previously required hours of skilled labor.
Key examples: • Product Visualization: Merge a product image with a new background in seconds (
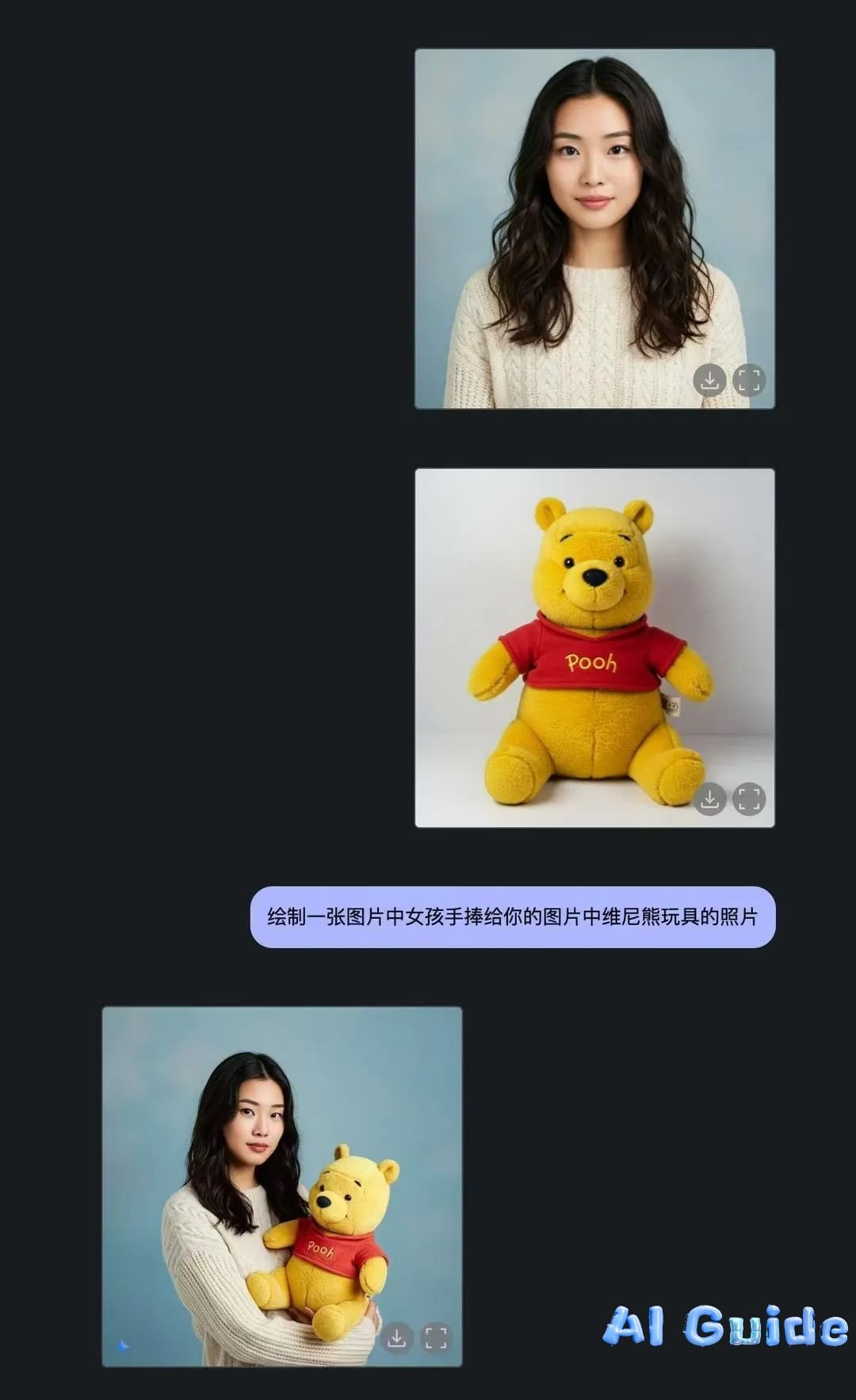
→

).
• Culinary Tutorials: Generate step-by-step recipe visuals from text prompts (

–

).
• Architectural Rendering: Transform sketches into photorealistic renders or floor plans into 3D walkthroughs.
3. Technical Backbone: How Gemini 2.0 Achieves This
Building on Google’s Gemma 3 architecture (27B parameters) and optimized via NVIDIA GPUs, Gemini 2.0 combines:
• Multimodal Fusion: Processes text prompts alongside pixel-level image data using cross-attention mechanisms.
• Adaptive Tokenization: Handles 128k-token contexts to manage complex scene manipulations.
• Ethical Safeguards: Integrated ShieldGemma 2 filters prevent misuse in sensitive applications.
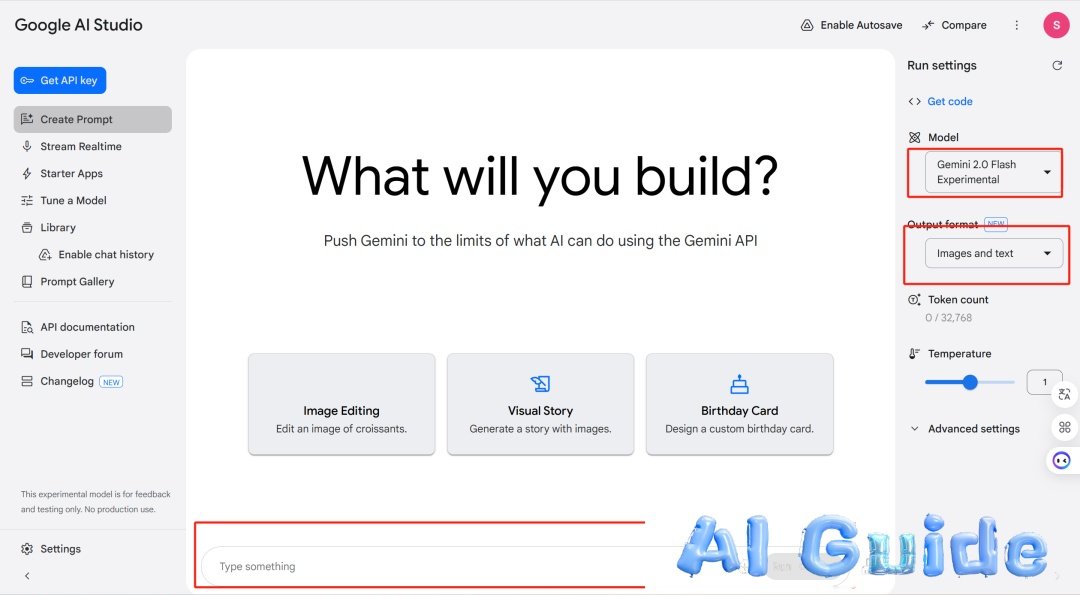
4. Hands-On Guide: Accessing the Future
To experiment with this tool:
Visit Google AI Studio (region-restricted access).
Select PREVIEW – Gemini 2.0 Flash Experimental (new) under models.
Choose Images and text output format.
Pro Tips: • Use iterative prompts for refinement (e.g., “Make the jersey sleeves longer” after initial generation).
• Leverage its chain-of-thought reasoning for multi-step tasks like recipe visualization.

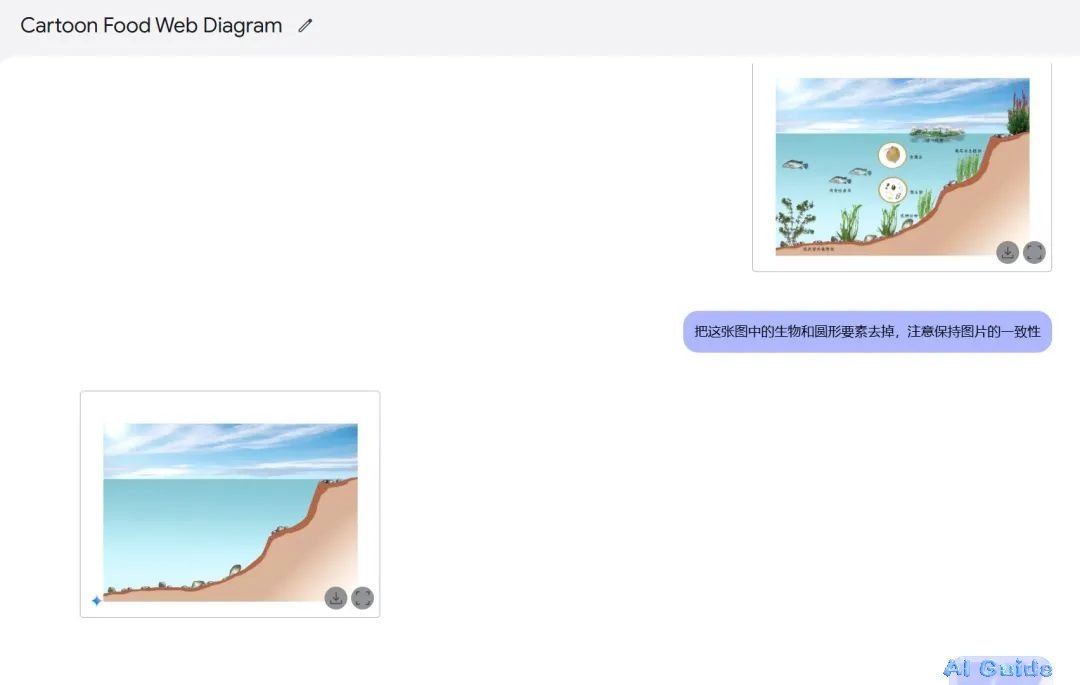
5. Beyond Static Images: The Conversational Workflow
Gemini 2.0’s dialog-driven interface allows dynamic adjustments:
User: “Remove the tree behind the girl.”
AI: Executes clean inpainti ng.
User: “Now add a sunset gradient to the sky.”
AI: Applies context-aware color grading.
This mirrors the capabilities of Google’s Gemini Robotics models, which enable real-time physical-world interactions through language commands.


6. The Bigger Picture: AI’s Creative Democratization
While fears about job displacement are valid, Gemini 2.0 also unlocks opportunities:
• Rapid Prototyping: Designers can iterate 100x faster.
• Micro-Entrepreneurship: Solo creators can produce studio-grade visuals without expensive software.
• Education: Students visualize complex concepts through intuitive prompts.
As Sundar Pichai noted at Google I/O 2023: “AI isn’t replacing humans—it’s redefining what they can achieve.”
Final Thought
Google’s latest move—coupling open-source Gemma 3 for developers with consumer-facing Gemini 2.0—signals a dual strategy: democratizing AI tools while pushing commercial-grade innovation. Those who master prompt engineering today will shape tomorrow’s creative economy.
“Adapt or be automated” is no longer a cliché—it’s the new reality.
: Google I/O 2023 AI updates
: Gemma 3 technical specifications
: NVIDIA-optimized Gemma 3 performance
: Gemini Robotics integration