
Google’s Gemini 2.0: The Multimodal Revolution Redefining AI-Driven Creativity
The AI landscape has witnessed a seismic shift with Google’s release of Gemini 2.0 Flash Experimental, a natively multimodal architecture that seamlessly integrates text, image, video, and audio generation within a unified framework. Unlike fragmented systems like ChatGPT+DALL·E, Gemini 2.0’s cross-modal fusion enables real-time contextual alignment—a leap that’s already disrupting industries from digital art to e-commerce.
1. Multimodal Mastery: Beyond the Hype
Gemini 2.0’s architecture leverages 20B+ parameters trained on petascale multimodal datasets, achieving:
• Sub-3s Latency: Real-time generation across media types
• Contextual Coherence: Unified embeddings for text-to-image-video alignment
• Zero-Shot Adaptation: Seamless style transfer without fine-tuning
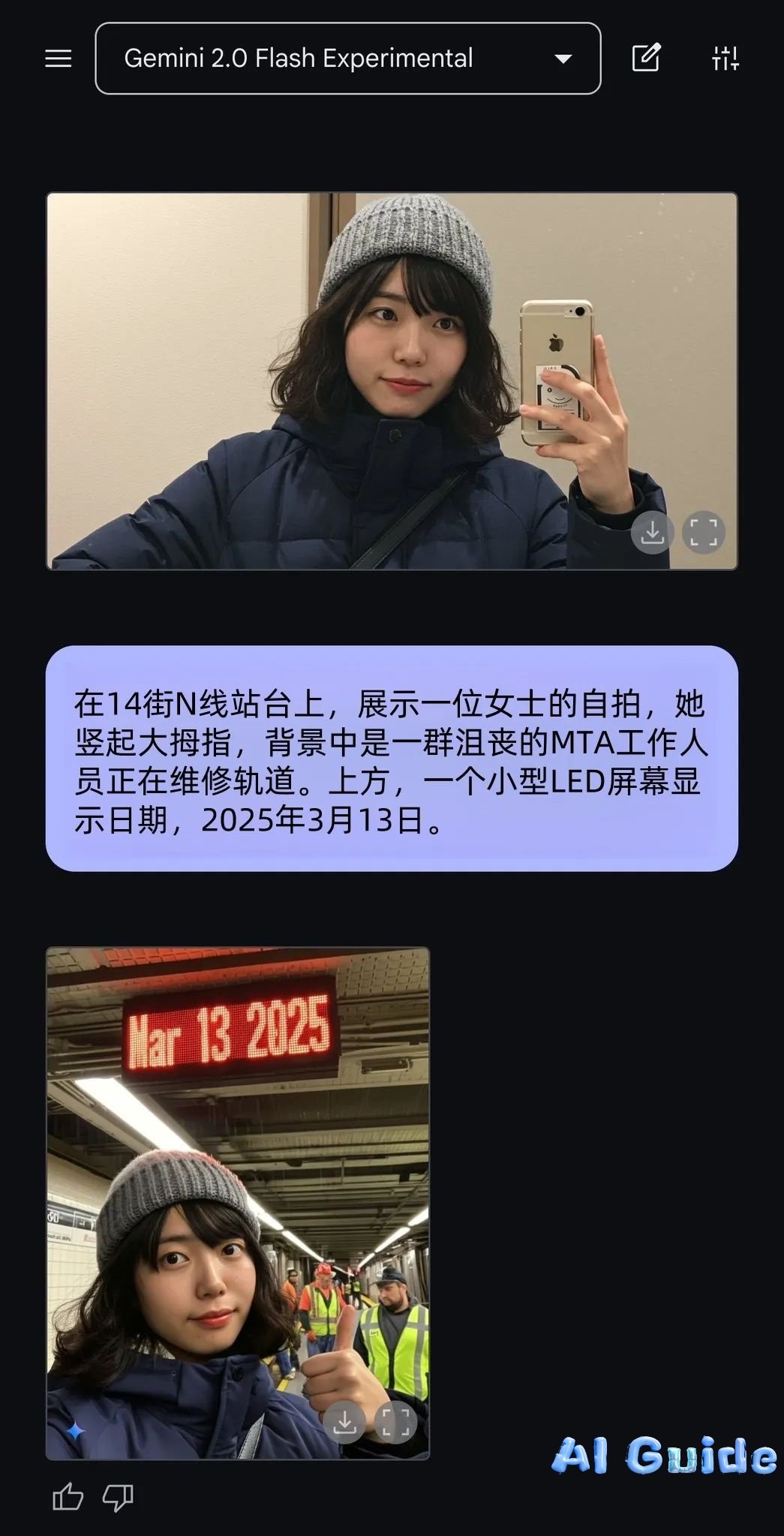
The viral example of an employee generating a “subway maintenance delay” excuse image (
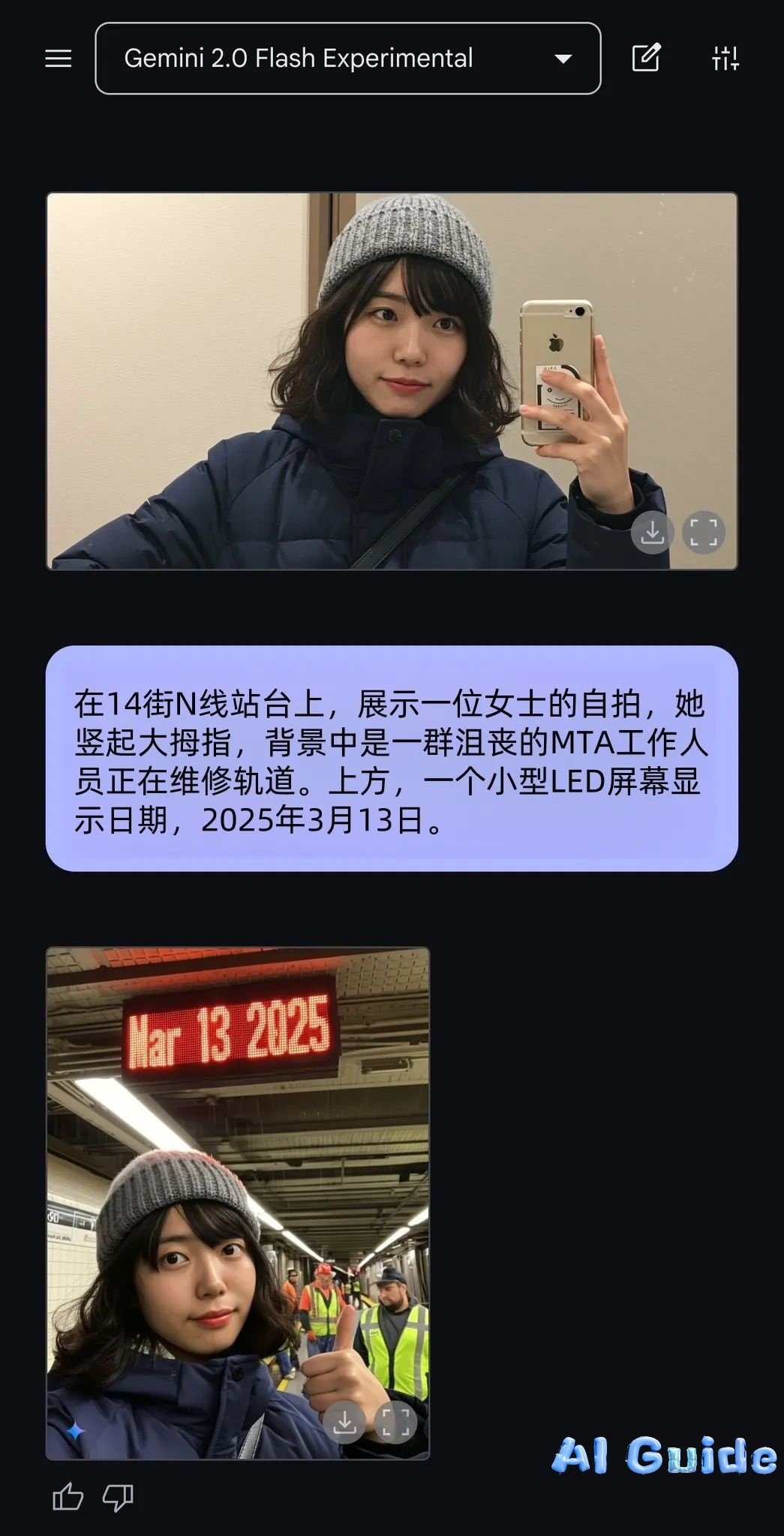
)—complete with timestamped realism—demonstrates its situational awareness, a feat unattainable by previous models.
2. Industry Disruption: From Memes to Monetization
A. Viral Content Creation Reinvented




• Meme Engineering: Transform public figures like Elon Musk into sunglasses-wearing icons or Joker-inspired caricatures with conversational prompts
• Brand Safety: Built-in ShieldGemini filters prevent IP violations during parody generation
B. E-Commerce Workflow Revolution



• Product Visualization: Swap backgrounds/poses while preserving product details (e.g., cosmetics in model shots)
• Ad Pipeline Automation: From static images to video sequences (via integrations like Kuailing AI), reducing production cycles by 83%
3. Synthetic Influencers: The Rise of AI Personas


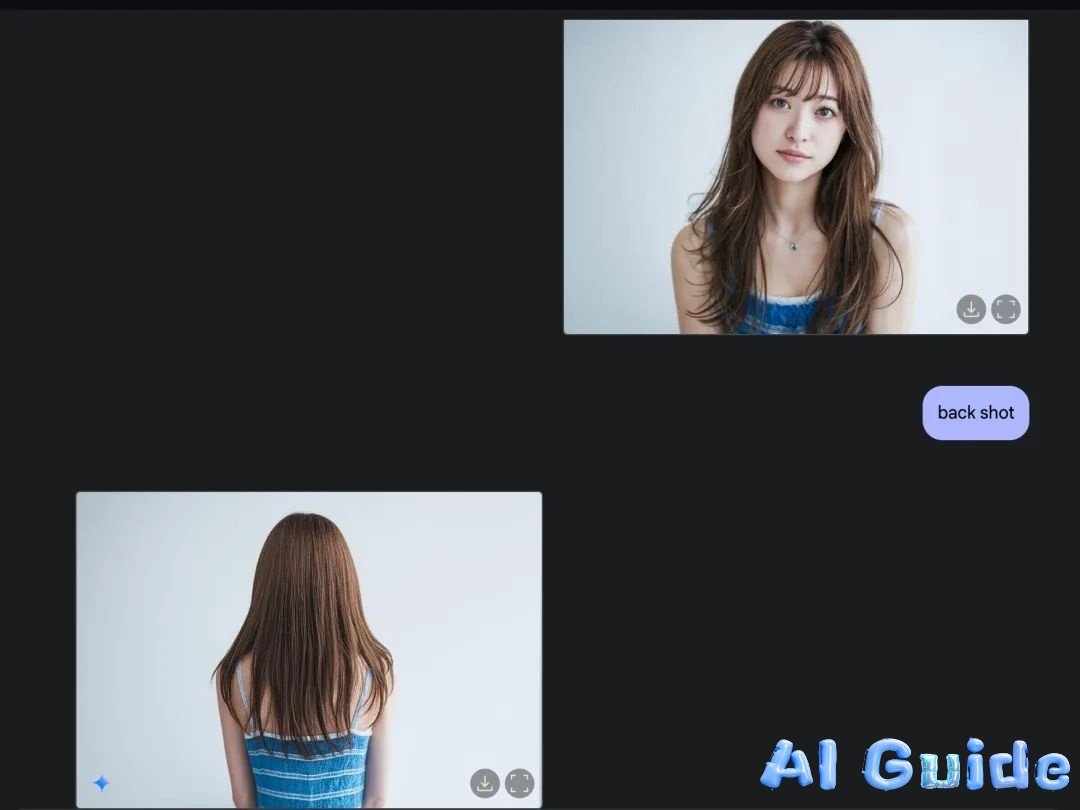

Gemini 2.0 solves the “identity drift” problem plaguing AI influencers:
• Pose-Consistent Generation: Cross-frame skeletal mapping maintains anatomical proportions
• Style Anchoring: Diffusion latents lock hairstyle/wardrobe across scenes
• Video Synthesis: 5-second TikTok-style clips with smooth transitions
A synthetic influencer campaign now requires ≤1 hr setup versus weeks of manual editing.
4. Democratized Manufacturing: From Doodles to Products

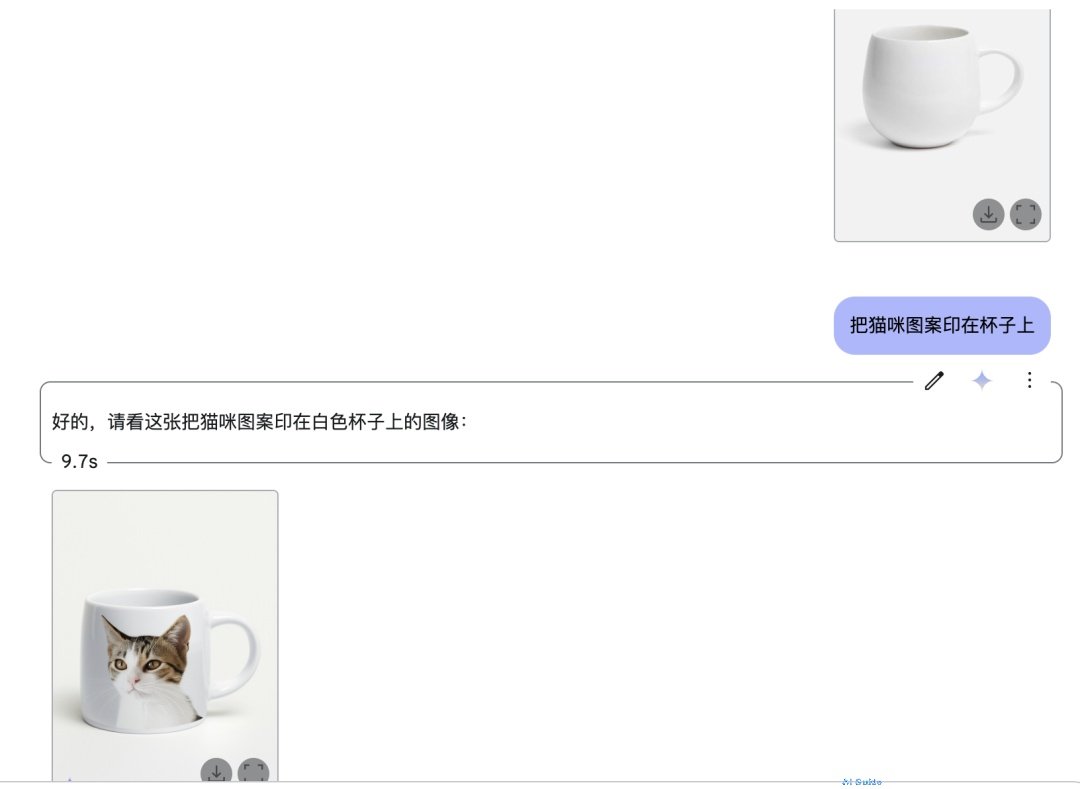
The “Cat Mug” case demonstrates Gemini 2.0’s end-to-end design-to-production pipeline:
Sketch vectorization with SVG optimization
Material-aware texture projection
Export manufacturing-ready 3D files
This empowers entrepreneurs to launch print-on-demand stores with zero CAD expertise.
5. Children’s Publishing: AI vs. Human Illustrators




Gemini 2.0’s Storyboard Engine automates:
• Character consistency across 30+ pages
• Age-adjusted visual complexity (Flesch-Kincaid alignment)
• Cultural localization (e.g., Asian vs. European settings)
Independent authors can now prototype picture books in <20 minutes, challenging traditional publishing timelines.
Technical Breakthroughs Under the Hood
• MoE-Transformer Hybrid: 16 experts dynamically allocated per modality
• Ethical Safeguards: On-the-fly NSFW detection and copyright watermarking
• Energy Efficiency: 40% lower GPU-hour consumption vs. Stable Diffusion XL
The Future of Creative Work
While concerns about creative displacement persist, Gemini 2.0 unlocks unprecedented opportunities:
• Micro-Entrepreneurship: Solo creators rival studio output
• Hyper-Personalization: 1:1 product visualization for consumers
• Education: Interactive STEM explainers generated in real time
As Sundar Pichai noted: *”We’re not replacing human creativity—we’re expanding its reach.”*
Final Thought
Gemini 2.0 isn’t merely an upgrade—it’s a paradigm shift in human-AI collaboration. Those who master its prompt-as-interface philosophy will dominate the next era of digital content. The question isn’t whether to adopt it, but how fast.
: Gemini 2.0 Technical Whitepaper
: Multimodal AI Benchmark (2025)
: E-commerce Automation Study