NVIDIA CEO Jensen Huang’s GTC Keynote Unveils Rubin Chip, Devours “DeepSeek Dividends,” and Sells Out Through 2027
Tech’s Taylor Swift, Prophet of Tokenomics, Moore’s Law Evangelist, and NVIDIA’s Newly Crowned “Chief Financial Disruptor” Jensen Huang Delivers Defining Annual Address
“People say my GTC keynote is the Super Bowl of AI,” Huang declared to a packed crowd at San Jose’s SAP Center on March 18, 2025. The event paralyzed downtown traffic as tens of thousands queued as early as 6 AM for the 10 AM spectacle. Over two hours, NVIDIA’s CEO unleashed a barrage of next-gen products: the Blackwell Ultra chip, Rubin architecture previews, Dynamo AI OS, photonic CPO switches, upgraded DGX supercomputers, and robotics platforms—all while addressing mounting market skepticism about NVIDIA’s dominance in the age of inference.
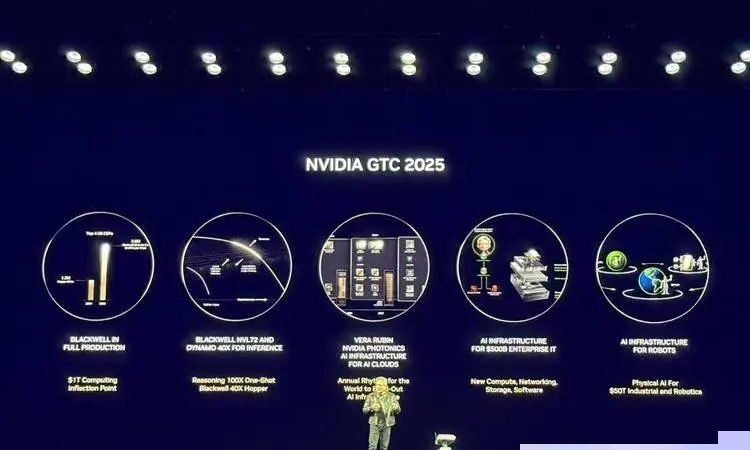
Core Announcements:
- Blackwell Ultra Superchip: Engineered for the “AI Inference Era,” delivering 1.5x performance gains over Hopper. Processes 1,000 tokens/sec on DeepSeek R1—slashing response times from 90 seconds to 10. Huang’s pitch: *”Buy more, earn more.”* Projects 50x revenue potential versus Hopper for data centers.
- Vera Rubin Next-Gen Architecture: 2026-bound successor with 4.2x memory and 2.4x bandwidth over Grace Blackwell. Features 88 CPU cores, 288GB HBM4, and a roadmap teasing Rubin Ultra (2027) and Feynman (2028) chips.
- Dynamo Inference OS: Open-source framework coordinating 1,000s of GPUs via “disaggregated services,” optimizing model reasoning/generation stages. Partnering with Perplexity.
- DGX Spark/Station: Consumer-grade AI supercomputers. The $3K Mac Mini-sized Spark offers 1 petaFLOP performance; the Station packs 20 petaFLOPS and 784GB memory.
- Isaac GROOT N1 Robotics: First open-source humanoid foundation model with physics-aware Newton Engine (co-developed with Google DeepMind/Disney).

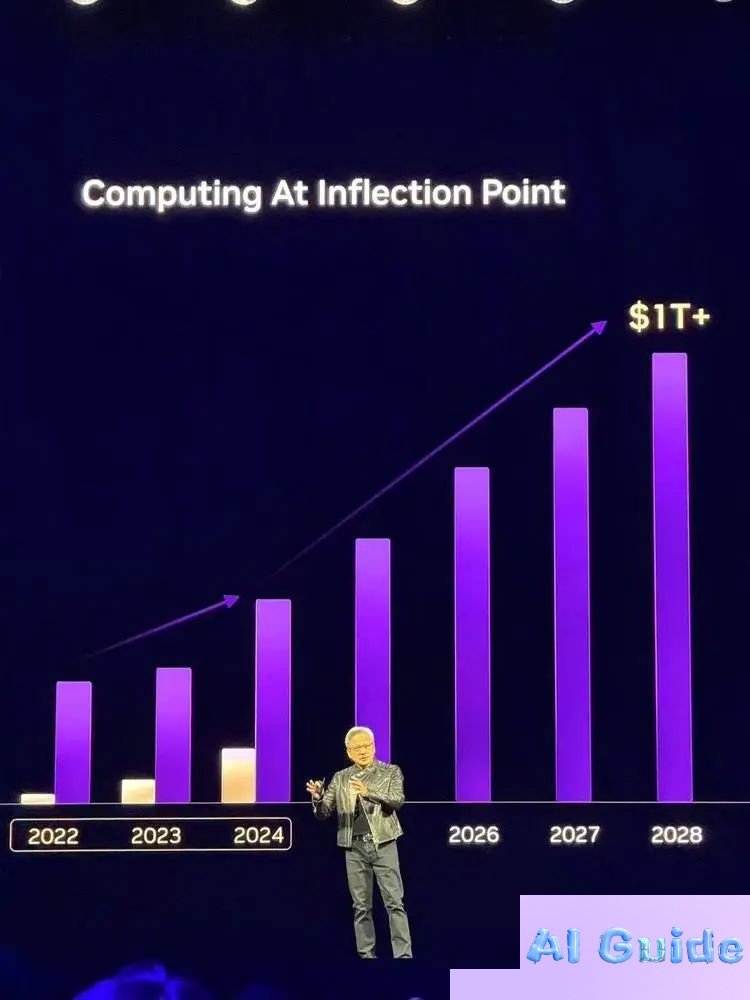
Tokenomics + AI Factories: How NVIDIA Plans to Capture the $1T Inference Boom
Unlike past keynotes where Huang set the agenda, 2025’s address confronted existential questions: Can NVIDIA maintain dominance as AI shifts from training to inference? The answer came via radical redefinition of computing economics.
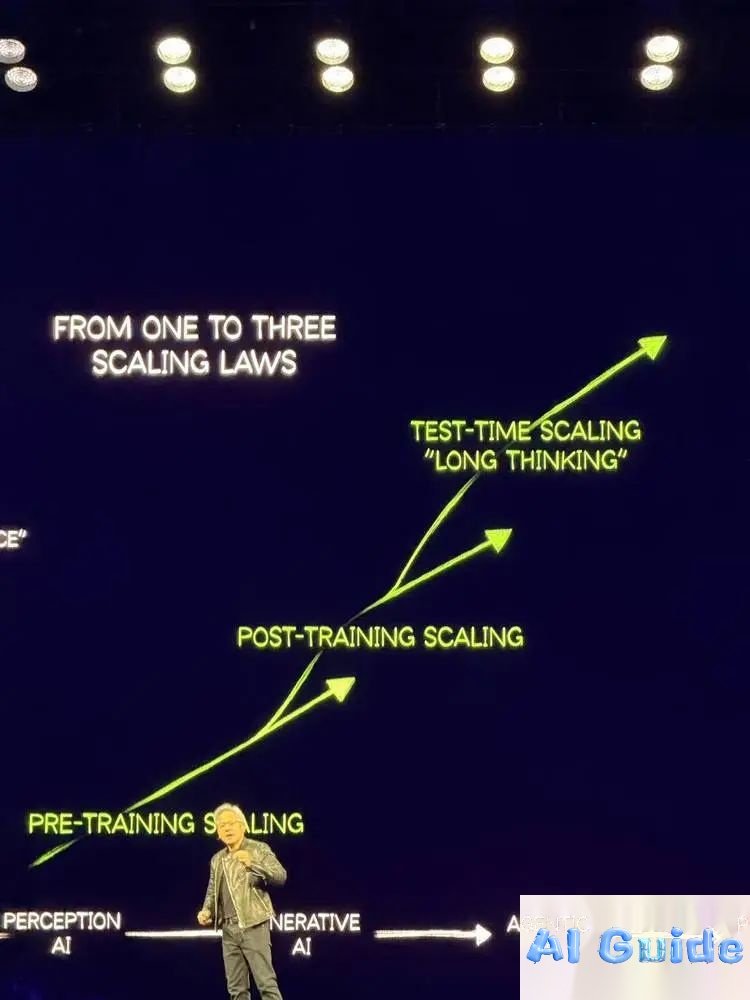
“Scaling laws didn’t end—they accelerated,” Huang asserted. He revealed that real-world AI inference now demands 100x more compute than 2024 projections, driven by:
- Chain-of-Thought Processing: Modern models like DeepSeek R1 generate 20x more tokens per query (e.g., 8,559 vs. Llama 3’s 439 for wedding seating plans).
- Latency Wars: Users demand responses within 2 seconds, forcing systems to process tokens 10x faster.
- Reinforcement Learning Costs: Training reasoning models requires trillions of tokens.
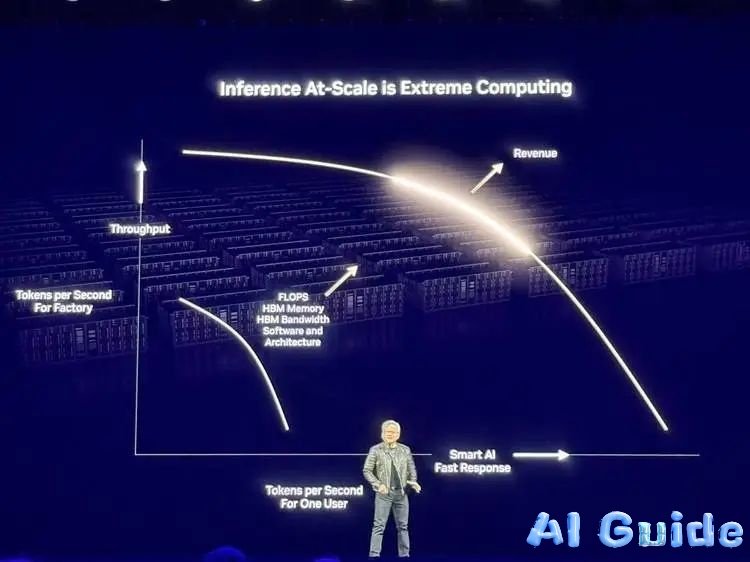
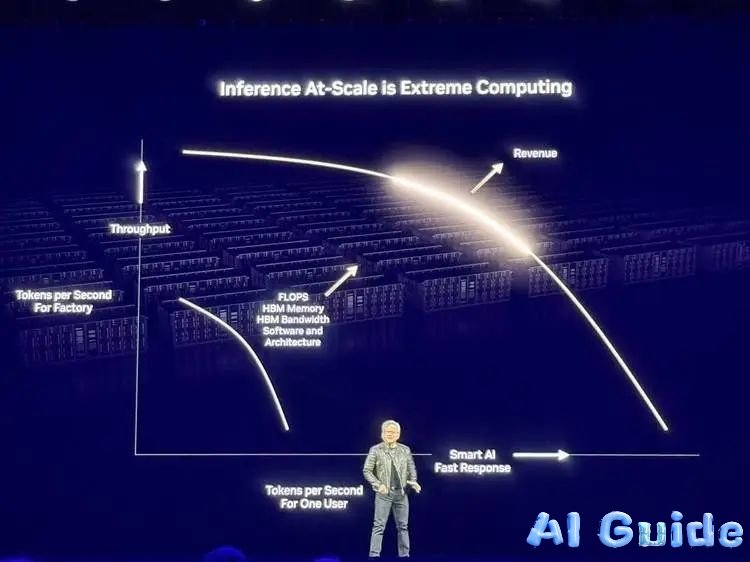
Huang’s solution? Tokenomics 2.0—framing data centers as “AI factories” where:
- Y-axis = Tokens per second per megawatt (operational efficiency)
- X-axis = User-facing tokens per second (revenue)
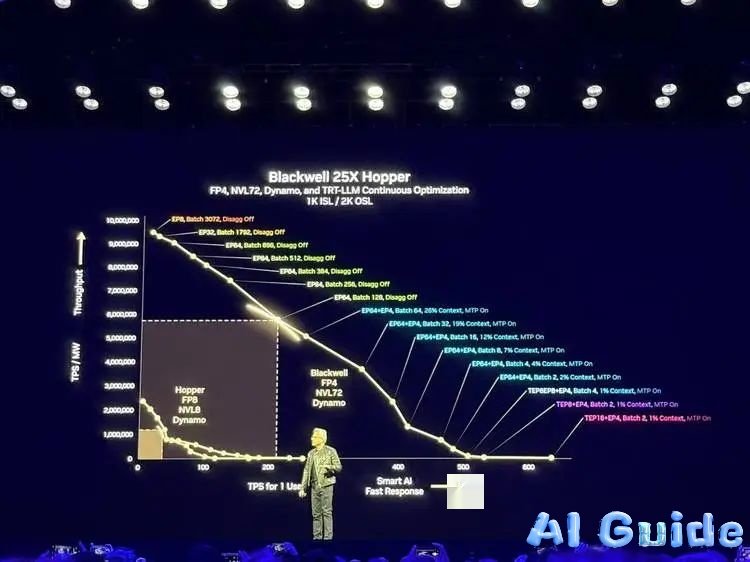
*”Blackwell pushes this profit curve beyond imagination,”* he demonstrated. A 1MW Blackwell cluster produces 25x more tokens than Hopper at equivalent power. For hyperscalers, upgrading to Blackwell Ultra could turn $1B Hopper farms into $50B revenue engines.
Even as Blackwell begins shipments (already accounting for $11B of Q1’s $39.3B revenue), Huang teased Rubin’s 2026 specs—effectively selling out 2027 inventory through strategic roadmap reveals.
Blackwell Ultra & Rubin: Engineering the $1T Datacenter
Blackwell Ultra Deep Dive
Now in full production, Blackwell’s GB300 NVL72 rack system connects 72 GPUs + 36 Grace CPUs, delivering:
- 9x faster inference vs. Hopper (10 sec vs. 90 sec responses)
- 50x revenue potential via DGX Cloud’s managed AI factories
- 11x speedup for LLMs on HGX B300 systems

Vera Rubin: 2026’s Architectural Leap
Named after dark matter pioneer Vera Rubin, this CPU/GPU combo features:
- 288GB HBM4 (4.2x Grace Blackwell’s capacity)
- 2.4x memory bandwidth
- 88-core CPU with 2x throughput
*”Everything’s new except the chassis,”* Huang quipped, while previewing 2027’s Rubin Ultra—a quad-GPU monolithic design.
Dynamo OS & Consumer AI: Democratizing the Inference Revolution
Dynamo: The AI Factory’s Nervous System
This open-source orchestrator splits model “thinking” (GPU cluster A) from “answering” (GPU cluster B), maximizing utilization. Early partner Perplexity aims to slash inference costs by 40%.
DGX Goes Mainstream
- DGX Spark: $3K desktop unit with 1 petaFLOP, 128GB RAM—capable of running 70B-parameter models locally.
- DGX Station: 20 petaFLOP beast for researchers, partnering with Dell/HP/ASUS.
Newton Robotics & Huang’s Reality Check
The keynote’s lighter moment came via Blue—a Disney-engineered robot running NVIDIA’s Newton physics engine. Its real-time simulation of soft/hard body interactions drew gasps as it bantered with Huang onstage.

Yet Huang tempered hype: *”Unlike buying laptops, building AI infrastructure requires years of planning—land, power, talent. We’ll keep delivering, but don’t expect shock-and-awe every quarter.”*
As NVIDIA’s market cap flirts with $3T, one truth emerges: The company isn’t just riding the AI wave—it’s redesigning the ocean.
